
这两天花了些时间写了一个关于翻译的爬虫,平时在看英文文献的时候需要用到翻译,但有时候感觉翻译出来的不是味道,然后又切换去另一个翻译页面再次翻译,感觉十分的麻烦,所以我便用爬虫爬取了欧路词典,有道翻译,百度翻译,谷歌翻译,并且将信息整合一起输出。
1 爬取欧路词典
之所以选择爬取欧路词典,是因为我以前用过,感觉翻译的效果也还不错,话不多说,直接上代码
def olu(content):
data={'to':'zh-CN','from':'en','text':content}
response=requests.post(url_olu,data=data,headers=oluheaders)
baidu_result=response.text
print('\n欧路词典:',baidu_result)怎么样是不是看起来很简单,欧路词典的data数据很简单来源于审查元素network的xhr文件里的Headers,from代表输入的语言类型,to代表输出的语言类型,text即为输入的内容,基本上所有的信息都在审查元素network的xhr文件里,最后response的文本就是返回的翻译内容,获取文本即可。
2 爬取有道词典
同样爬取有道词典我们也要获取审查元素里network的xhr文件,不过有道翻译做了一点反爬机制,如果你按照它的request url输入会得到一个error的报错,需要对此进行修改,真的是坑。代码如下:
def youdao(content):
data={
'i':content,
'from':'AUTO',
'to':'AUTO',
'smartresult':'dict',
'client':'fanyideskweb',
'salt':'1533907163550',
'sign':'e8fb6c81be653475e67a42f06ee7c679',
'doctype':'json',
'version':'2.1',
'keyfrom':'fanyi.web',
'action':'FY_BY_CLICKBUTTION',
'typoResult':'false'
}
response=requests.post(url_youdao,data=data,headers=ydheaders)
result=response.json()
length=len(result['translateResult'][0])
fanyi_result=''
for i in range(length):
fanyi_result=fanyi_result+result['translateResult'][0][i]['tgt']
print('\n有道翻译:',fanyi_result+'\n')其实我后面发现data数据可以不必全部提交也行
3 爬取百度翻译
吐槽一下百度翻译就是个纸老虎,因为在爬取百度翻译的时候我才发现data里的sign一直在不断变化,每次提交的信息不一样数据也在变,我百度的时候说这是百度翻译对此加密了,需要在js文件里找到加密代码进行编译输出正确的提交,我也照做了,最后发现还是不行,后面我想到了有道的反爬就心血来潮一试,结果没想到他居然也是把request url改了,跟它的sign没有半毛钱关系。简直无语,代码如下(只放了英译中的):
def baidu(content):
# sign=findsign(content)
# data={'from':'en','to':'zh','query':content,'transtype':'translang','simple_means_flag':'3','sign':sign,'token':'d3e57e8f690ef485d54ee9dd68e0da30'}
data={'from':'en','to':'zh','query':content}
response=requests.post(url_baidu,data=data,headers=bdheaders)
baidu_result=response.json()
print('百度翻译:',baidu_result['data'][0]['dst']+'\n')加#注释部分是我一开始的输入,后面慢慢探索发现就只要输入三个就行。
4 爬取谷歌翻译
不得不说还是谷歌的反爬做的最好,它也引入了一个tk码,而且还和前面的request url结合起来了,所以不得不破解这个算法,但网上已经有大神破译了这种算法我就直接拿来写了一个库,在代码的开头import就行了,代码如下:
def google(content):
tk = js.getTk(content)
param = {'tk': tk, 'q': content}
result = requests.get("""http://translate.google.cn/translate_a/single?client=t&sl=en
&tl=zh-CN&hl=zh-CN&dt=at&dt=bd&dt=ex&dt=ld&dt=md&dt=qca&dt=rw&dt=rm&dt=ss
&dt=t&ie=UTF-8&oe=UTF-8&source=btn&ssel=3&tsel=6&kc=0""", params=param,headers=ggheaders)
fanyi_ans=result.json()
length=len(fanyi_ans[0])
fanyi_answer=''
for i in range(length-1):
fanyi_answer=fanyi_answer+fanyi_ans[0][i][0]
print('谷歌翻译:',fanyi_answer+'\n')最后我用py2exe库生成了exe文件,让其在普通的没有安装python的Windows下也能执行,运行效果如下(由于中译英用的少便没有爬取欧路词典了):
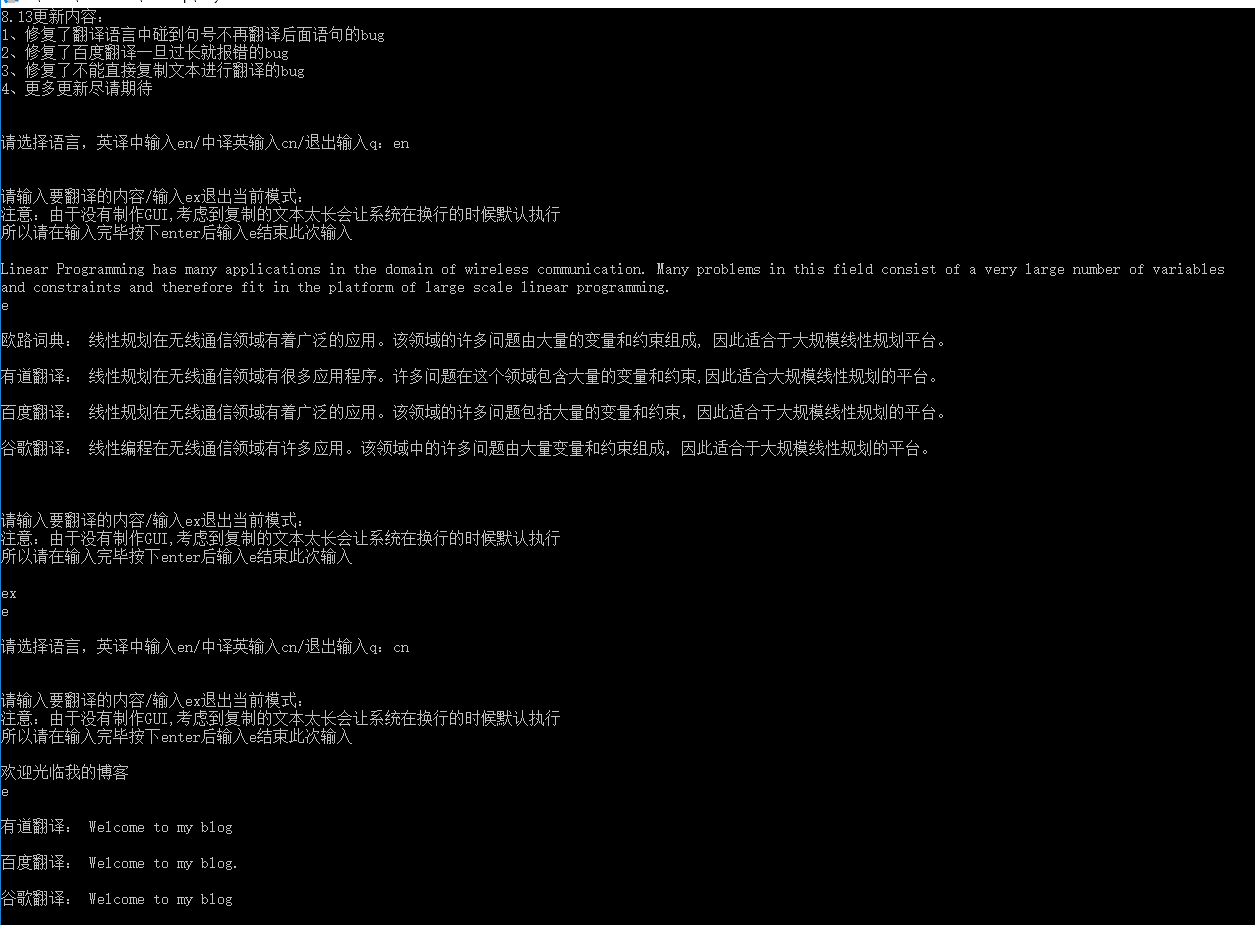
这是我自己利用爬虫做的第一个对我来说有用的东西,个人感觉实用性还不错,当然还有许多需要加强的地方,以后再慢慢改进。
相关代码:https://github.com/miraclewk/Fanyi
exe程序下载:链接: https://pan.baidu.com/s/1CbQDU_8QBQrtbl_23Tek6w 密码: 8hsk
自己这两天一直在用,感觉还不错,而且越用越好用,嘻嘻,总算是学以致用了,开心(*^▽^*)
还发现了一个新优点,就是你复制一大段英文到谷歌翻译或其他翻译时,需要将其整合成连续的一行,谷歌翻译出来的结果才是连续的,而我这个不需要,只是多需要按一个e结束输入,另外我这个还可以对前面的翻译结果有个记录,可以随时往前翻看所有的结果,哈哈